MySql 主从热备份工作原理
简单的说:就是主服务器上执行过的操作会被保存在binLog日志里面,从服务器把他同步过来,然后重复执行一遍,那么它们就能一直同步啦。
我们进一步详细介绍原理的细节, 这有一张图:
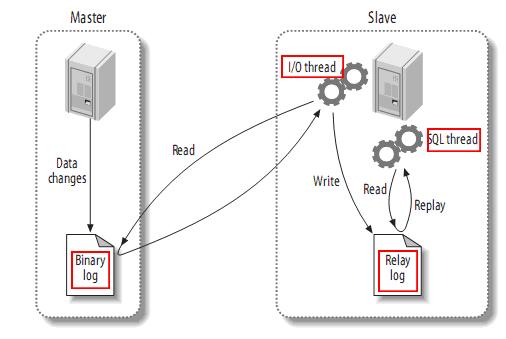
以上是一个主-从复制(热备)的例子。
整体上来说,复制有3个步骤:
- 作为主服务器的Master,会把自己的每一次改动(每条sql语句)都记录到二进制日志Binarylog中。
- 作为从服务器Slave, 会用master上的账号登陆到 master上,读取master的Binarylog,写入到自己的中继日志 Relaylog。
- 然后从服务器自己的sql线程会负责读取这个中继日志,并执行一遍。
到这里主服务器上的更改就同步到从服务器上了,这种复制和重复都是mysql自动实现的,我们只需要配置即可。
整个过程,MySQL使用3个线程来执行复制同步功能,其中两个线程(Sql线程和IO线程)在从服务器,另外一个线程(IO线程)在主服务器。
主-主互相复制实际只是把上面的例子反过来再做一遍。
所以我们以这个例子介绍原理。
实际操作
实际操作是
主服务器, 配置要记录在binLog里面的数据库,同时设置一个给从服务器登录的账号。
从服务器, 配置relayLog,配置主服务器的地址和端口,还有主服务器给的登录账号。
在主服务器上设置给从服务器登录用的账号
rant replication slave on *.* to 'relay_user1'@'192.168.1.168' identified by 'pass123456';
注意:
从服务器地址为:192.168.1.168,换成你的从机器的IP地址,这样就只允许从服务器登录,相对安全些。
用户名为: relay_user1
密码为: pass123456,自己按需要修改。修改MySQL配置文件
如果有Workbench,可以在左边的Navigator栏找到Options File,然后进行配置,如果想直接修改配置文件,文件的位置请看结尾的后记3.主服务器的my.cnf配置
log-bin=master-a-bin binlog-format=ROW //二进制日志的格式,有row、statement和mixed三种类型 server-id=1//要求各个服务器的这个id必须不一样 binlog-do-db=test //我们想让主服务器记录下操作的数据库。好让从服务器去复制的。 auto_increment_offset = 1 //设置AUTO_INCREMENT起点,关于这个看后记4 auto_increment_increment = 10 //设置AUTO_INCREMENT增量 //下面是一些别的配置,你可以跳过不看的 ////////////////////////////////////////// gtid-mode=on //启用GTID,可看结尾的后记2说明 enforce-gtid-consistency=true //启用GTID master-info-repository=TABLE//默认是file,选择table方式保存 relay-log-info-repository=TABLE//默认是file,选择table方式保存 sync-master-info=1 //实时同步 slave-parallel-workers=2 //设定从服务器的SQL线程数;0表示关闭多线程复制功能 binlog-checksum=CRC32 //日志校验 master-verify-checksum=1//启用校验 slave-sql-verify-checksum=1//启用校验 innodb_flush_log_at_trx_commit=1 //每N次事务提交或事务外的指令都需要把日志写入(flush)硬盘 sync_binlog=1 //This makes MySQL synchronize the binary log’s contents to disk each time it commits a transaction从服务器的my.cnf配置
log-bin=master-a-bin.log binlog-format=mixed//请保持这两个一致 server-id=2 auto_increment_offset = 1 auto_increment_increment = 10 log-slave-updates=true //log-slave-updates 意思是,中继日志执行之后,这些变化是否需要计入自己的binarylog。 当你的从服务器需要作为另外一个服务器的主服务器的时候需要打开。 就是双主互相备份,或者多主循环备份。 我们这里需要, 所以打开。 //配置主服务器相关的信息 replicate-do-db = test report-host = 192.168.0.101 report-user = repl_user report-password = 112122 report-port = 3306 //别的一些配置,可以跳过不看 sync_binlog=1 gtid-mode=on enforce-gtid-consistency=true master-info-repository=TABLE relay-log-info-repository=TABLE sync-master-info=1 slave-parallel-workers=2 binlog-checksum=CRC32 master-verify-checksum=1 slave-sql-verify-checksum=1 binlog-rows-query-log-events=1这样就算配置完咯,我不会告诉你我是用workbench改的,然后在apply的时候,把它复制下来粘贴到这里的,需要注意的是,如果你数据库原本就有表创建了,从服务器没有这个表的话,
请手动创建一个,
请手动创建一个,
请手动创建一个。
因为这个建表语句在这个同步操作前就执行过,没保存啊。我已经帮你试过了,下面试错误日志里面的信息.2015-10-05 22:00:32 2628 [Warning] Slave: Table 'test.user' doesn't exist Error_code: 1146 2015-10-05 22:00:32 2628 [ERROR] Error running query, slave SQL thread aborted. Fix the problem, and restart the slave SQL thread with "SLAVE START". We stopped at log 'bin0001.000003' position 151另外需要说的是,如果遇到这样的错误,请改正后重启下。
重启同步
1
2
3
4stop slave;
change master to master_host='192.168.0.101',master_user='repl_user',master_password='pass123456',master_auto_position=1;
start slave;既然都配置好了,那就重启下,让配置生效
可以在主服务器打印下信息,看下有没启动成功先的
mysql> show master status ;
从服务器;
mysql> show slave status ;
如果打印的内容中,下面两句后面都为yes,那就恭喜你,正常运行咯slave_io_running : yes slave_sql_running : yesSlave_IO_Running: 是否要从Master复制二进制数据
Slave_SQL_Running: 是否执行从Master复制过来的二进制数据
Slave_IO_Running和Slave_SQL_Running的值均为Yes时为同步开启;
前面已经说过了,从服务器会有两个线程的,一个IO线程和一个执行sql的线程。说到这里,我不得不吐槽下在window下的cmd那个界面有多那么让人想死。
真的可以让人抓狂的。

然后试下在主服务器插入点数据,在从服务器能否同步回来? 如果不能请打开errLog.err或者xxx.err之类的文件。
W7用户:
错误日志在:C:\ProgramData\MySQL\MySQL Server 5.6\data\你的电脑名.err
搭配问题
单一master和多slave
多Slave之间并不相互通信,只能与master进行通信。如下:
如果写操作较少,而读操作很多时,可以采取这种结构。
你可以将读操作分布到其它的slave,从而减小master的压力。
但是,
当slave增加到一定数量时,slave对master的负载以及网络带宽都会成为一个严重的问题。
这种结构虽然简单,但是,它却非常灵活,足够满足大多数应用需求。
一些建议:
(1) 不同的slave扮演不同的作用(例如使用不同的索引,或者不同的存储引擎);
(2) 用一个slave作为备用master,只进行复制;
(3) 用一个远程的slave,用于灾难恢复;主动模式的Master-Master (双主热备)
Master-Master复制的两台服务器,既是master,又是另一台服务器的slave。如图:

主动的Master-Master复制有一些特殊的用处。
例如,地理上分布的两个部分都需要自己的可写的数据副本。
这种结构最大的问题就是更新冲突。
假设一个表只有一行(一列)的数据,其值为1,如果两个服务器分别同时执行如下语句:
在第一个服务器上执行:
mysql> UPDATE tbl SET col=col + 1;
在第二个服务器上执行:
mysql> UPDATE tbl SET col=col * 2;
那么结果是多少呢?一台服务器是4,另一个服务器是3,但是,这并不会产生错误。
实际上,MySQL并不支持其它一些DBMS支持的多主服务器复制(Multimaster Replication),这是MySQL的复制功能很大的一个限制(多主服务器的难点在于解决更新冲突),但是,如果你实在有这种需求,你可以采用MySQL Cluster,以及将Cluster和Replication结合起来,可以建立强大的高性能的数据库平台。
但是,可以通过其它一些方式来模拟这种多主服务器的复制。主动-被动模式的Master-Master (Master-Master in Active-Passive Mode)
这是master-master结构变化而来的,它避免了M-M的缺点,实际上,这是一种具有容错和高可用性的系统。它的不同点在于其中一个服务只能进行只读操作。
如图:
带 从服务器的Master-Master结构(Master-Master with Slaves)

这种结构的优点就是提供了冗余。在地理上分布的复制结构,它不存在单一节点故障问题,而且还可以将读密集型的请求放到slave上。
后记
1. 整体架构图
最后我们想搭建一个下面这样的的集群环境

- 负载均衡– ApacheServer版本 / Nginx版本
- 双热备 / 读写分离( Mysql + keepalived )
- 缓存Redis集群
- 动静分离
2. 关于MySql5.6的新特性
由于Mysql 5.6 引入了 GTID(Global Transaction ID),保证 Slave 在复制的时候不会重复执行相同的事务操作;
其次,是用全局事务 IDs代替由文件名和物理偏移量组成的复制位点,定位 Slave 需要复制的 binlog 内容,在旧的 binlog 事件基础上新增两类事件
- Previous_gtids_log_event 该事件之前的全局事务 ID 集合
- Gtid_log_event 标记之后的事务对应的全局事务 ID
MySQL 5.6 的 binlog 文件中,每个事务的开始不是 “BEGIN” ,而是 Gtid_log_event 事件。

详解可以参考 https://gitsea.com/wp-content/uploads/2013/06/MySQL_Innovation_Day_Replication_HA.pdf
优点:
使用 GTIDs 作为主备复制的位点,在写 binlog 时用 Gtid_log_event 标记事务
主从复制不再基于master的binary logfile和logfile postition,从服务器连接到主服务器之后,把自己曾经获取到的GTID(Retrieved_Gtid_Set)发给主服务器,主服务器把从服务器缺少的GTID及对应的transactions发过去即可.
采用多个sql线程,每个sql线程处理不同的database,提高了并发性能,即使某database的某条语句暂时卡住,也不会影响到后续对其它的database进行操作.
对比:
以前采用类似于C语言那样的文件和偏移量的方式来做的。这个要是偏移没同步好,出的就是一堆bug,现在是一个一个事务队列的样式,相对安全了。
3.配置文件的位置
window下
一开始以为配置文件是安装的MySql目录下的my-default.ini,后来用workbench发现配置文件是在C:\ProgramData\MySQL\MySQL Server 5.6\my.ini。
mac下是在/etc/my.cnf;
4. 自增长的主键
1 | auto_increment_offset = 1// 设置AUTO_INCREMENT起点 |
这两个用于在双主(多主循环)互相备份。 因为每台数据库服务器都可能在同一个表中插入数据,如果表有一个自动增长的主键,那么就会在多服务器上出现主键冲突。 解决这个问题的办法就是让每个数据库的自增主键不连续。
我假设将来可能需要 10 台服务器做备份, 所以auto-increment-increment 设为10。而 auto-increment-offset=1 表示这台服务器的序号。 从1开始,不超过auto-increment-increment。
这样做之后, 我在这台服务器上插入的第一个id就是 1, 第二行的id就是 11了, 而不是2。(同理,在第二台服务器上插入的第一个id就是2, 第二行就是12, 这个后面再介绍) 这样就不会出现主键冲突了。
但是
我们显然无法预期后面业务到底会增长到个什么样,用这样的方法,很可能在以后为自己留下一个坑,例如,如果我的服务器超过10台的时候,怎么办呢?设置成200的增量?
还是弄个UUID吧,这样相对安全可扩展性好点,虽然先对比较长了。
不过如果根据实际业务需求,确实觉得没那个必要和可能,那就可以用上面的方式做。
5. 双主热备份
关于如何做双主热备份,其实你可以理解为,原来的从服务器变成了主服务器,主服务器变成了从服务器,这样,他们就互为主从,变成双主热备份啦!!是不是?所以你只需要把配置文件copy一份,就好了。
不清楚的可参考这篇文章
参考的文章:
学一点 mysql 双机异地热备份—-快速理解mysql主从,主主备份原理及实践
6.主服务器原本就有数据怎办?
如果原本主服务器就有数据,而且没有开启记录操作,保存到binLog里面去,那就冷备份呗。倒出一份然后到从服务器上跑一圈。